2023 was a year of numerous strides at CCV and in the research community here at Brown. Thank you for your continued participation and support.
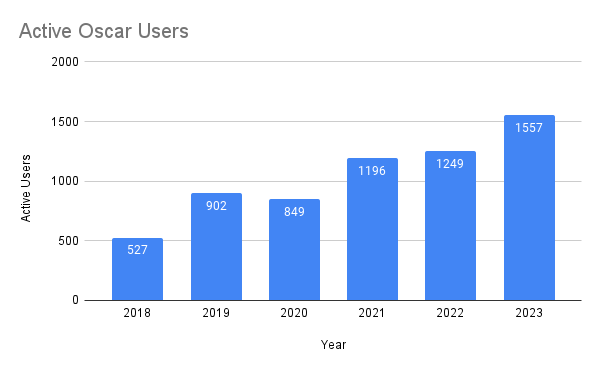
Here are some quick statistics from our Brown community made in 2023. We had 1557 active Oscar users, which is a 24.66% increase in activity from the year prior. Over 3.6 million jobs were run in Oscar totalling over 57 million CPU core hours! Since 2018, the number of active oscar users has increased as well as demand for resources. Over 470 questions were asked and helped in our weekly office hours.

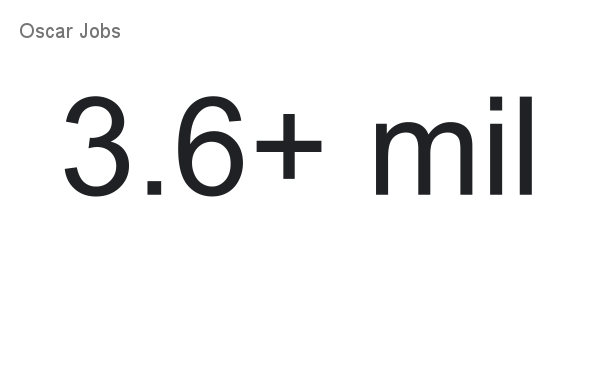

In June, Oscar transitioned from General Parallel File System (GPFS) to an all-flash parallel filesystem (VAST data) as its primary storage pool. And furthermore, it was done without any major issues. This is arguably the biggest change Oscar has gone through in the last 10 years!
Alongside supporting Oscar for high-performance computing needs, CCVers provided academic support to the Brown community. We hosted 17 Data Science, Computing, and Visualization Workshops (DSCoVs) with the Data Science Initiative (DSI). Topics included Gene Annotation Resources in R, ChatGPT's API and Prompt Engineering, Building VR Application in Unity, and more! Jupyterhub, cloud-hosted Jupyter Notebooks for multiple users, supported 8 undergraduate and graduate courses. In June, we hosted a bootcamp, a series of online/hybrid tutorials, wherein over 175 members of the Brown community signed up to learn about research computing resources and get hands-on practice using Oscar.
In 2023, we supported 60 projects and collaborations throughout Brown. The following are some highlights from those projects.
- We launched our first mobile applications: SOMA, an app focused on pain management, and MAPPS, an app designed to explore social interactions and their influence on disease transmission patterns.
- Honeycomb released versions 3.1 and 3.2 which better align the repository with jsPsych best practices.
- Hierarchical Sequential Sampling Modeling (HSSM) —a contemporary Python toolbox integrating cutting-edge likelihood approximation methods within the Python Bayesian ecosystem—was released on the Python Package Index (PyPI) in late June.
- We developed and released two packages in Julia, a rising programming language in the data science space. IceFloeTracker.jl was created in collaboration with the Wilhelmus Lab for tracking ice floes using moderate resolution imaging spectroradiometer (MODIS) data. Chamber.jl is a Julia package for simulating the eruption of a volcano using a model for the frequency of eruptions of upper crustal magma chambers based on Degruyter and Huber (2014).
- In collaboration with the Behavior and Neurodata Core (BNC), we developed and released a versatile utility script to streamline data exports to Oscar, led two XNAT Workshops for the neuroimaging community, and contributed to the MNE-BIDS open-source project. Furthermore, we enhanced the XNAT-to-BIDS exporting pipeline to accommodate EEG and Physiological data, highlighting our collective commitment to optimizing neuroimaging workflows and fostering open-source collaboration.
- We continued to support the local and state governments with advertising and getting collaborators for their public policy projects: North Carolina Project Portal, Research Partnerships Portal of the City of San Antonio in Texas
- We helped the Autonomous Empirical Research Group, whose mission is to use cutting-edge machine learning techniques to automate the process of making and reproducing scientific discoveries, to reorganize their Python package and their processes to easily accept contributions from potentially hundreds of researchers from around the world.
Thank you to our wonderful team! In 2023, Anna Murphy, Prithvi Thakur, Galen Winsor, and Heather Yu, joined our growing CCV team. We look forward to the journey ahead in 2024.
